
|
Hello All !! Welcome to my tiny corner on the web. I am a final year PhD student in the Machine Learning Department (MLD) at CMU, where I am advised by Prof. Zico Kolter. I also collaborate frequently with Prof. Aditi Raghunathan. My research focuses on understanding the interplay between pretraining and post-training of foundation models, and using these insights to scale the two efficiently. Prior to CMU, I was a Research Fellow at Microsoft Research, India advised by Dr. Prateek Jain. I worked on EdgeML, developing ML algorithms for severely resource constrained devices. Earlier, I spent 4 amazing years at IIT Bombay. |
|
|
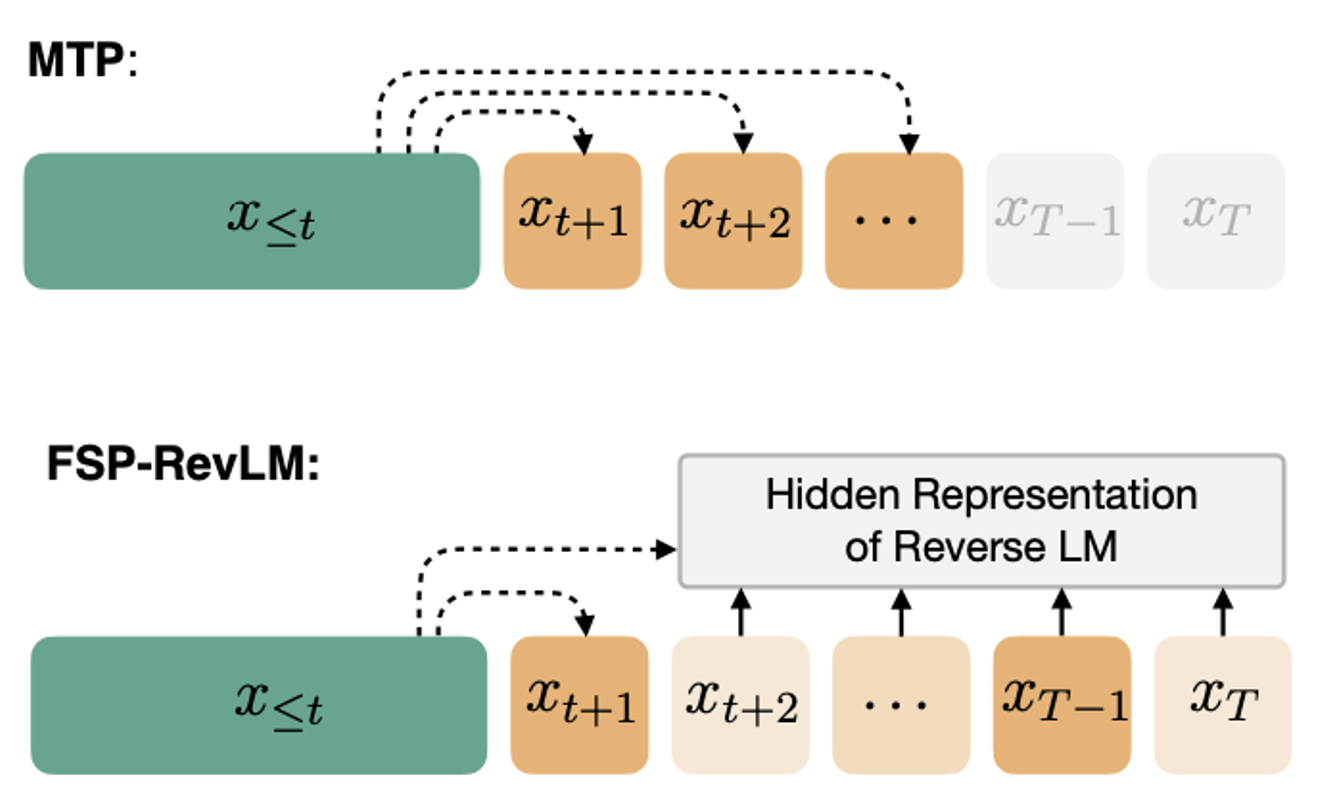
|
|
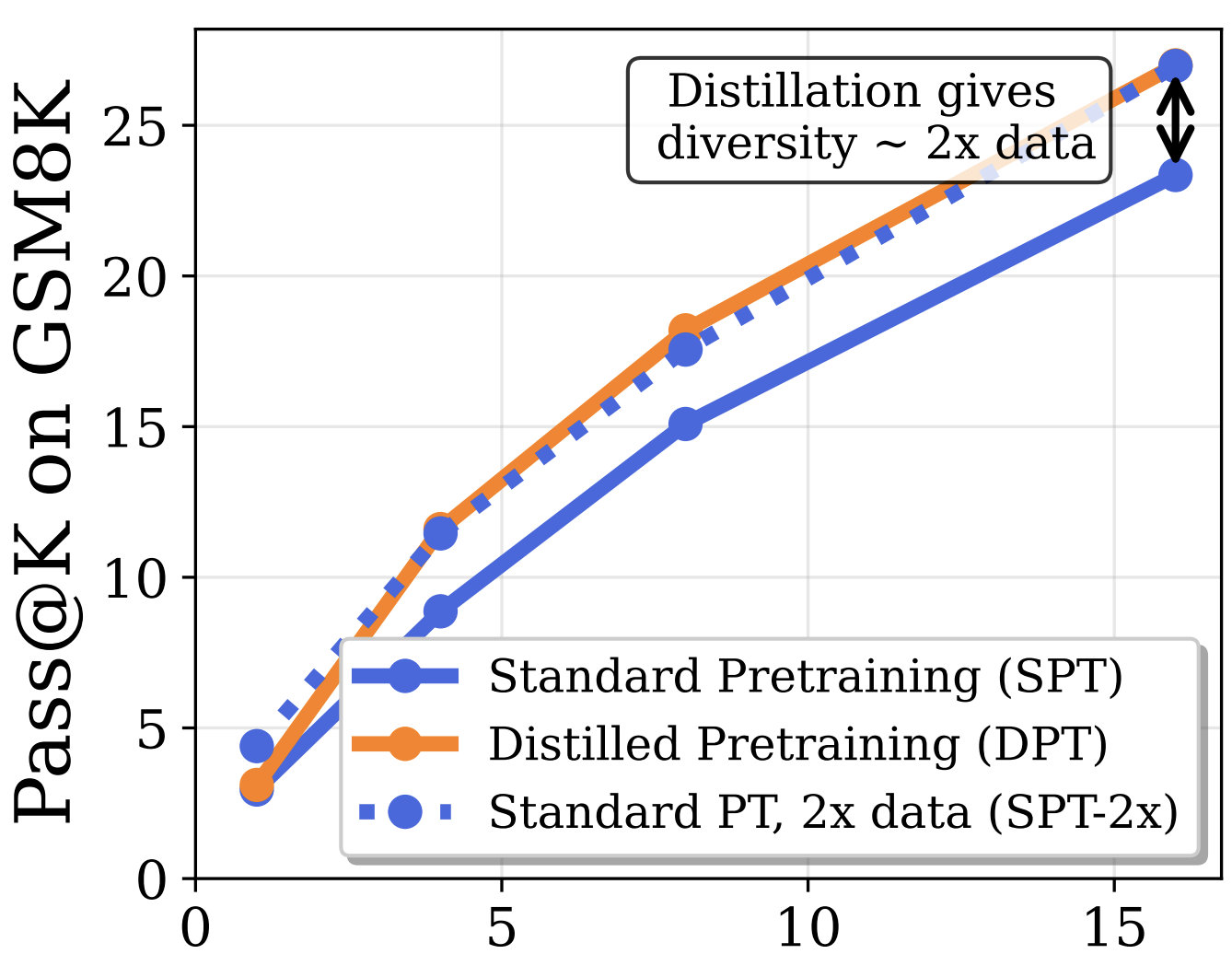
|
|

|
|
|
|

|
|
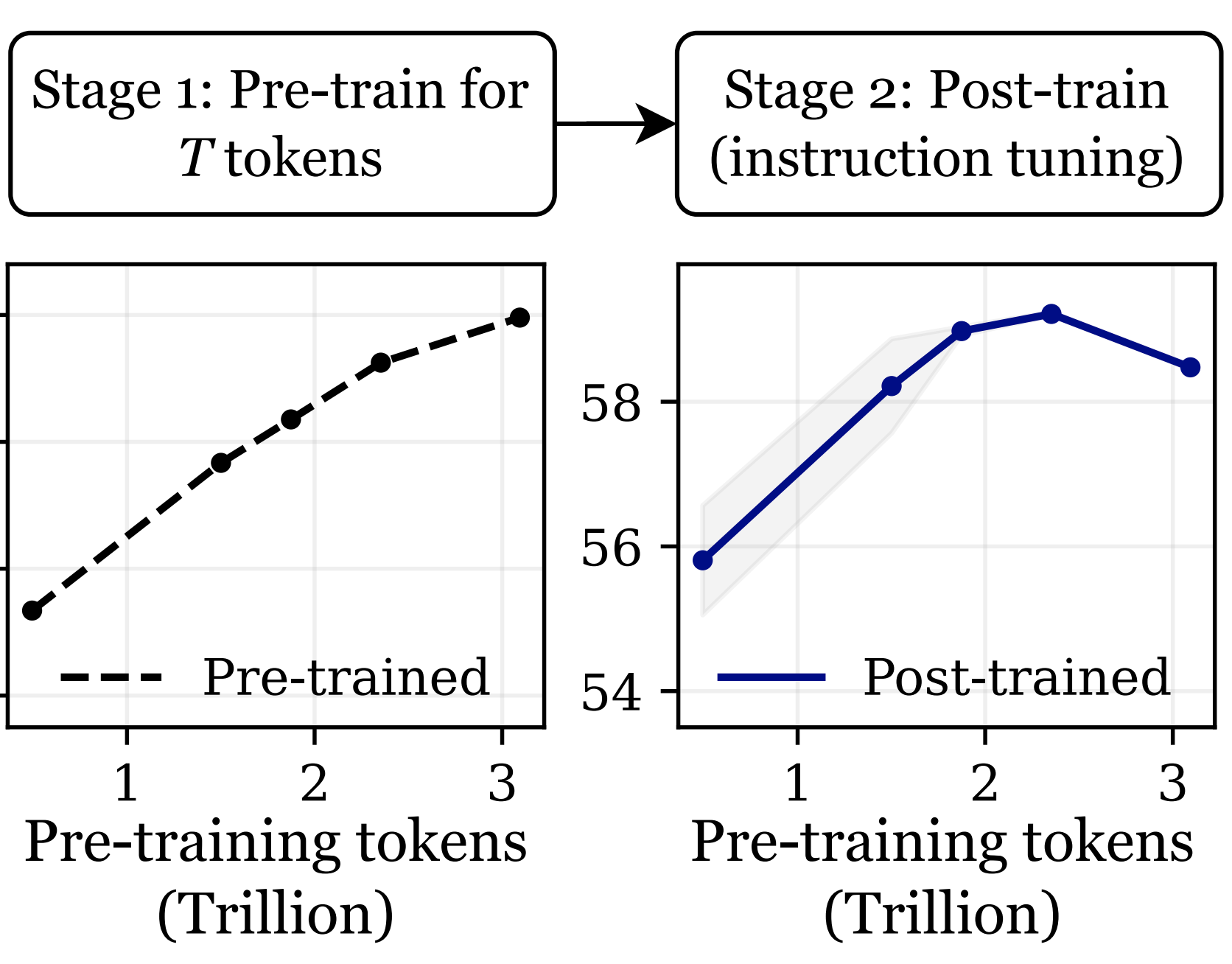
|
|
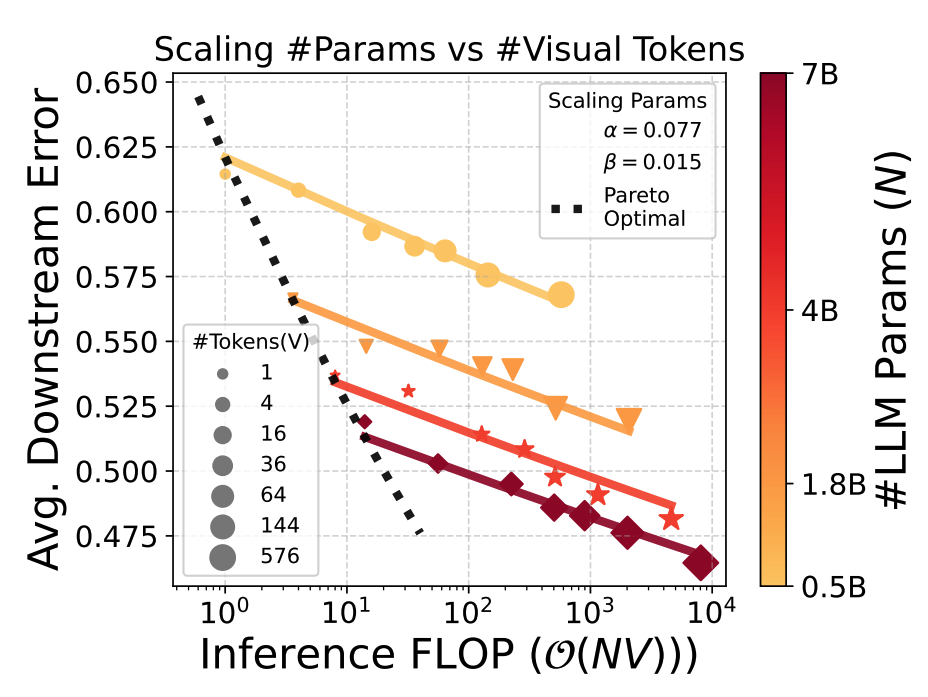
|
|
|
|
|
|
|
abstract /
paper
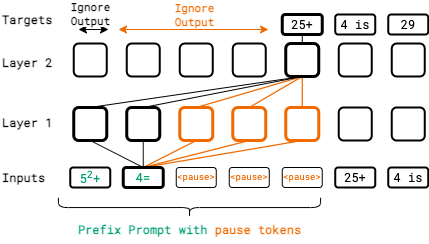
Language models generate responses by producing a series of tokens in immediate succession: the (K +1)th token is an outcome of manipulating K hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, K+10 hidden vectors, before it outputs the (K+1)th token? We operationalize this idea by performing training and inference on language models with a (learnable) pause token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate pause-training on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains on our tasks when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on eight tasks, most prominently, a gain of 18% EM score on the QA task of SQuAD, 8% on CommonSenseQA and 1% accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm. |
|
abstract /
paper /
project page
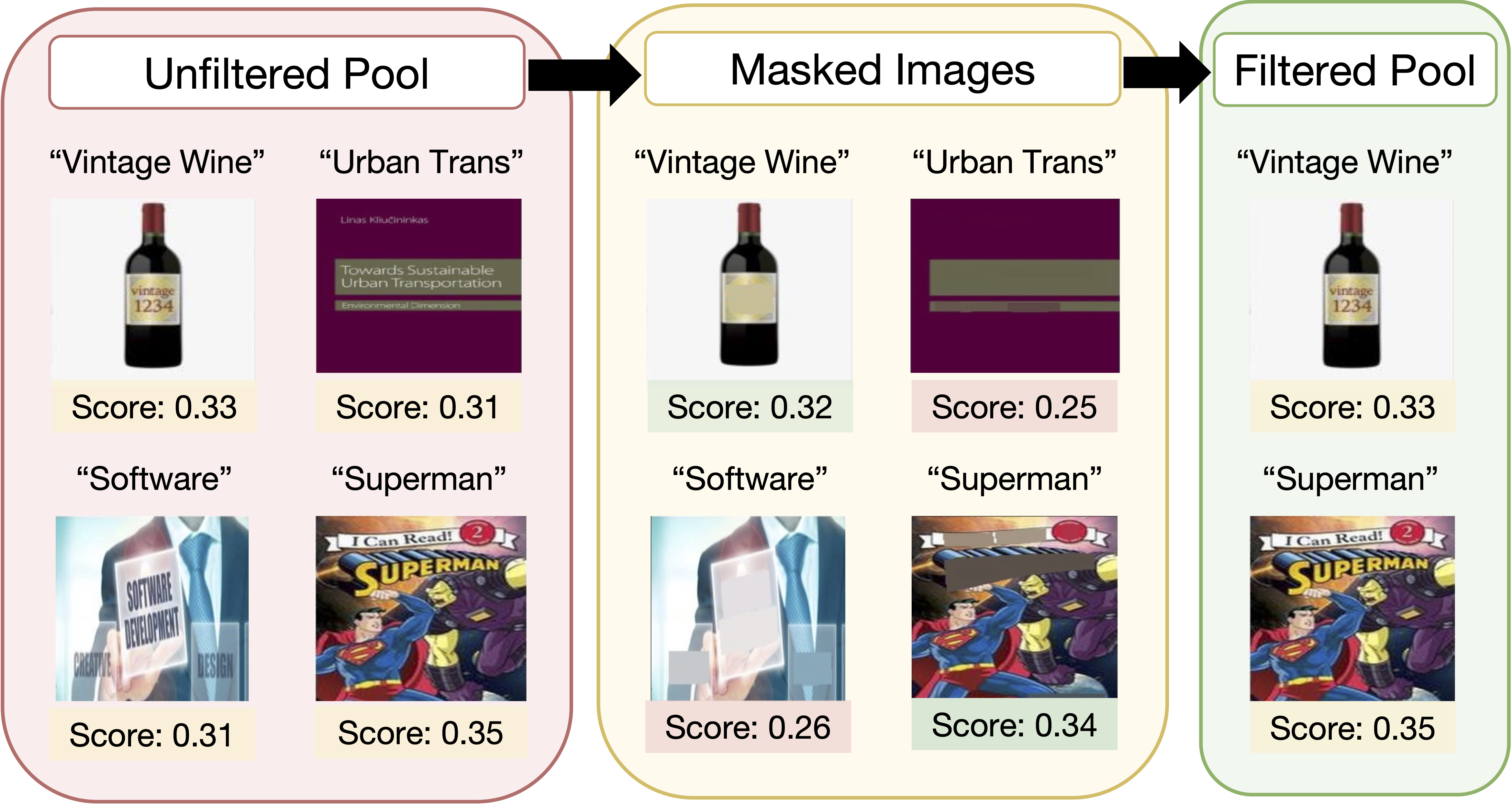
Large web-sourced multimodal datasets have powered a slew of new methods for learning general-purpose visual representations, advancing the state of the art in computer vision and revolutionizing zero- and few-shot recognition. One crucial decision facing practitioners is how, if at all, to curate these ever-larger datasets. For example, the creators of the LAION-5B dataset chose to retain only image-caption pairs whose CLIP similarity score exceeded a designated threshold. In this paper, we propose a new state-of-the-art data filtering approach motivated by our observation that nearly 40% of LAION's images contain text that overlaps significantly with the caption. Intuitively, such data could be wasteful as it incentivizes models to perform optical character recognition rather than learning visual features. However, naively removing all such data could also be wasteful, as it throws away images that contain visual features (in addition to overlapping text). Our simple and scalable approach, T-MARS (Text Masking and Re-Scoring), filters out only those pairs where the text dominates the remaining visual features -- by first masking out the text and then filtering out those with a low CLIP similarity score of the masked image. Experimentally, T-MARS outperforms the top-ranked method on the "medium scale" of DataComp (a data filtering benchmark) by a margin of 6.5% on ImageNet and 4.7% on VTAB. Additionally, our systematic evaluation on various data pool sizes from 2M to 64M shows that the accuracy gains enjoyed by T-MARS linearly increase as data and compute are scaled exponentially. |
|
abstract /
paper /
talk
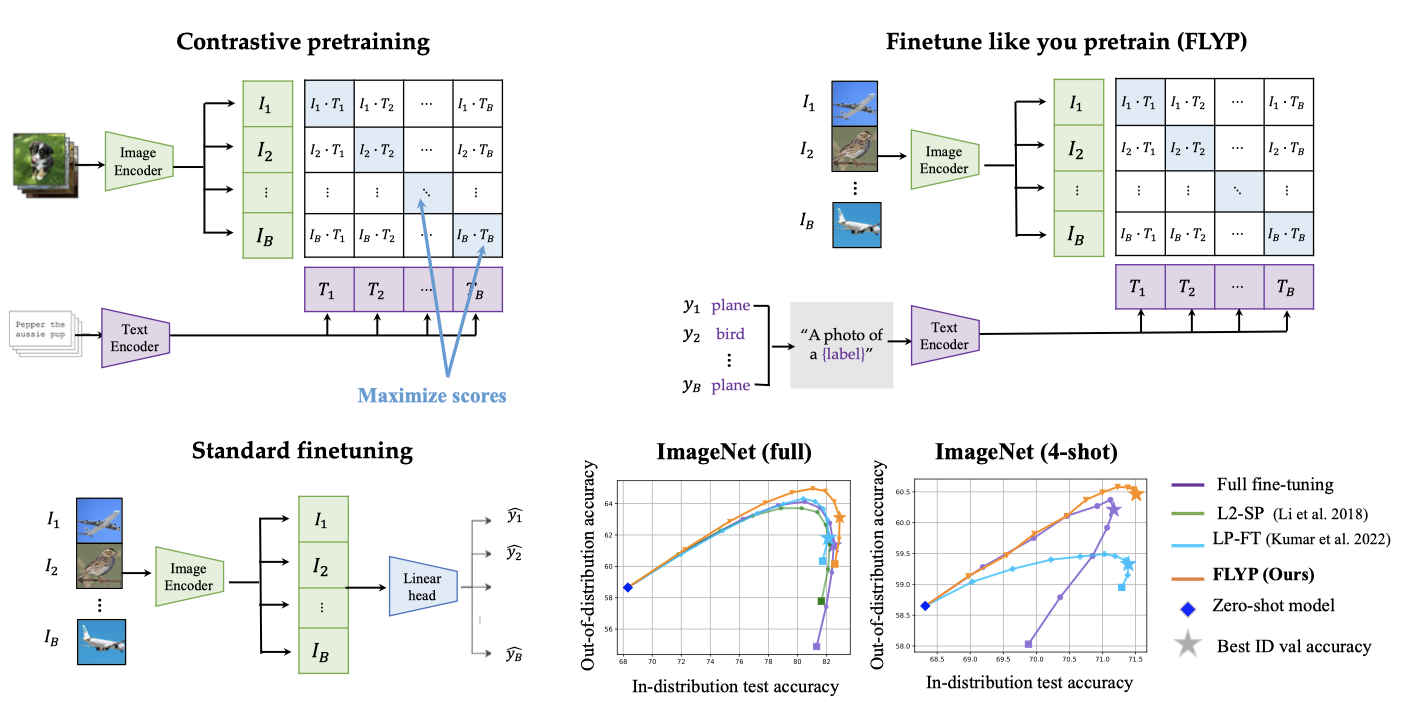
Finetuning image-text models such as CLIP achieves state-of-the-art accuracies on a variety of benchmarks. However, recent works like WiseFT (Wortsman et al., 2021) and LP-FT (Kumar et al., 2022) have shown that even subtle differences in the finetuning process can lead to surprisingly large differences in the final performance, both for in-distribution (ID) and out-of-distribution (OOD) data. In this work, we show that a natural and simple approach of mimicking contrastive pretraining consistently outperforms alternative finetuning approaches. Specifically, we cast downstream class labels as text prompts and continue optimizing the contrastive loss between image embeddings and class-descriptive prompt embeddings (contrastive finetuning). Our method consistently outperforms baselines across 7 distribution shifts, 6 transfer learning, and 3 few-shot learning benchmarks. On WILDS-iWILDCam, our proposed approach FLYP outperforms the top of the leaderboard by 2.3% ID and 2.7% OOD, giving the highest reported accuracy. Averaged across 7 OOD datasets (2 WILDS and 5 ImageNet associated shifts), FLYP gives gains of 4.2% OOD over standard finetuning and outperforms the current state of the art (LP-FT) by more than 1% both ID and OOD. Similarly, on 3 few-shot learning benchmarks, our approach gives gains up to 4.6% over standard finetuning and 4.4% over the state of the art. In total, these benchmarks establish contrastive finetuning as a simple, intuitive, and state-of-the-art approach for supervised finetuning of image-text models like CLIP. |
|
abstract /
paper /
talk
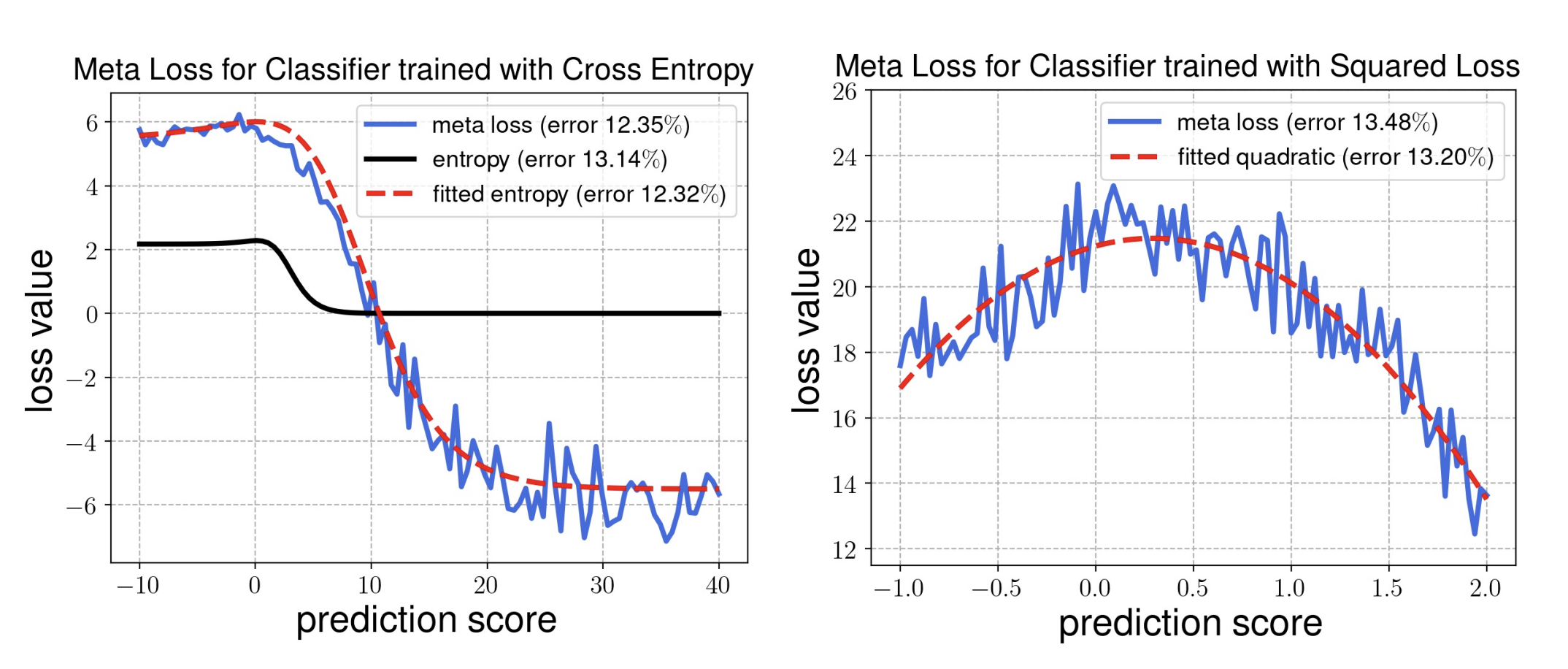
Test-time adaptation (TTA) refers to adapting neural networks to distribution shifts, with access to only the unlabeled test samples from the new domain at test-time. Prior TTA methods optimize over unsupervised objectives such as the entropy of model predictions in TENT [Wang et al., 2021], but it is unclear what exactly makes a good TTA loss. In this paper, we start by presenting a surprising phenomenon: if we attempt to meta-learn the best possible TTA loss over a wide class of functions, then we recover a function that is remarkably similar to (a temperature-scaled version of) the softmax-entropy employed by TENT. This only holds, however, if the classifier we are adapting is trained via cross-entropy; if trained via squared loss, a different best TTA loss emerges. To explain this phenomenon, we analyze TTA through the lens of the training losses's convex conjugate. We show that under natural conditions, this (unsupervised) conjugate function can be viewed as a good local approximation to the original supervised loss and indeed, it recovers the best losses found by meta-learning. This leads to a generic recipe that can be used to find a good TTA loss for any given supervised training loss function of a general class. Empirically, our approach consistently dominates other baselines over a wide range of benchmarks. Our approach is particularly of interest when applied to classifiers trained with novel loss functions, e.g., the recently-proposed PolyLoss, where it differs substantially from (and outperforms) an entropy-based loss. Further, we show that our approach can also be interpreted as a kind of self-training using a very specific soft label, which we refer to as the conjugate pseudolabel. Overall, our method provides a broad framework for better understanding and improving test-time adaptation. Code is available at https://github.com/locuslab/tta_conjugate. |
|
abstract /
paper
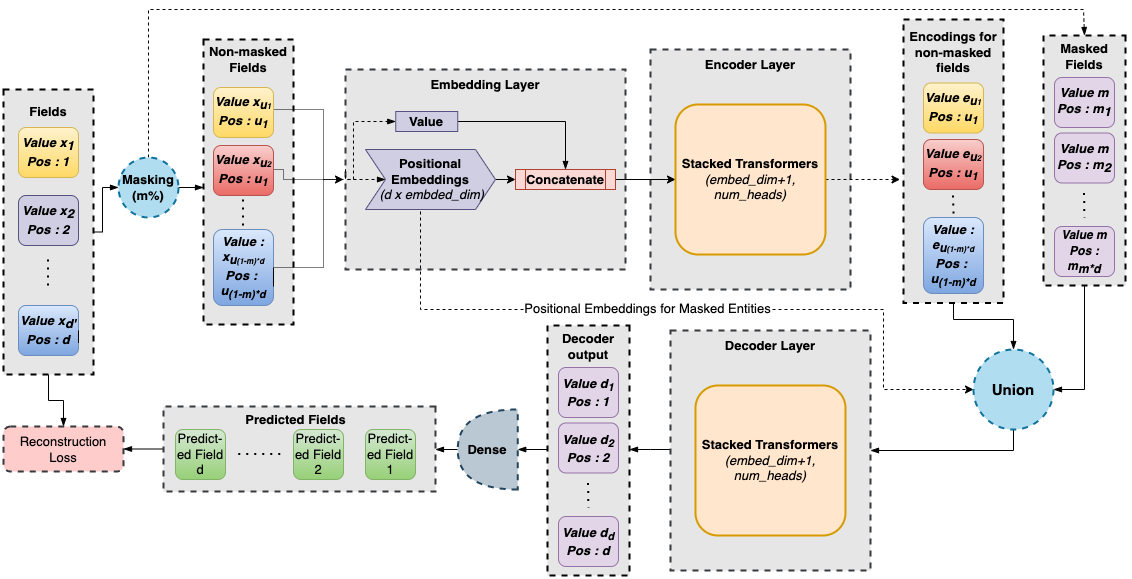
We consider the task of self-supervised representation learning (SSL) for tabular data: tabular-SSL. Typical contrastive learning based SSL methods require instance-wise data augmentations which are difficult to design for unstructured tabular data. Existing tabular-SSL methods design such augmentations in a relatively ad-hoc fashion and can fail to capture the underlying data manifold. Instead of augmentations based approaches for tabular-SSL, we propose a new reconstruction based method, called Masked Encoding for Tabular Data (MET), that does not require augmentations. MET is based on the popular MAE approach for vision-SSL [He et al., 2021] and uses two key ideas: (i) since each coordinate in a tabular dataset has a distinct meaning, we need to use separate representations for all coordinates, and (ii) using an adversarial reconstruction loss in addition to the standard one. Empirical results on five diverse tabular datasets show that MET achieves a new state of the art (SOTA) on all of these datasets and improves up to 9% over current SOTA methods. We shed more light on the working of MET via experiments on carefully designed simple datasets. |
|
abstract /
paper
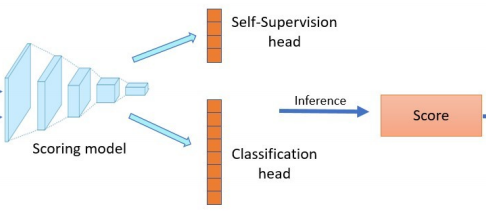
The goal of pool-based active learning is to judiciously select a fixed-sized subset of unlabeled samples from a pool to query an oracle for their labels, in order to maximize the accuracy of a supervised learner. However, the unsaid requirement that the oracle should always assign correct labels is unreasonable for most situations. We propose an active learning technique for deep neural networks that is more robust to mislabeling than the previously proposed techniques. Previous techniques rely on the task network itself to estimate the novelty of the unlabeled samples, but learning the task (generalization) and selecting samples (out-of-distribution detection) can be conflicting goals. We use a separate network to score the unlabeled samples for selection. The scoring network relies on self-supervision for modeling the distribution of the labeled samples to reduce the dependency on potentially noisy labels. To counter the paucity of data, we also deploy another head on the scoring network for regularization via multi-task learning and use an unusual self-balancing hybrid scoring function. Furthermore, we divide each query into sub-queries before labeling to ensure that the query has diverse samples. In addition to having a higher tolerance to mislabeling of samples by the oracle, the resultant technique also produces competitive accuracy in the absence of label noise. The technique also handles the introduction of new classes on-the-fly well by temporarily increasing the sampling rate of these classes. |
|
abstract /
paper /
code /
video
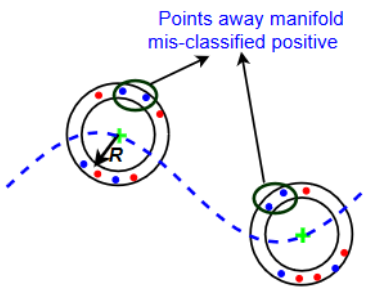
Classical approaches for one-class problems such as one-class SVM and isolation forest require careful feature engineering when applied to structured domains like images. State-of-the-art methods aim to leverage deep learning to learn appropriate features via two main approaches. The first approach based on predicting transformations (Golan & El-Yaniv, 2018; Hendrycks et al., 2019a) while successful in some domains, crucially depends on an appropriate domain-specific set of transformations that are hard to obtain in general. The second approach of minimizing a classical one-class loss on the learned final layer representations, e.g., DeepSVDD (Ruff et al., 2018) suffers from the fundamental drawback of representation collapse. In this work, we propose Deep Robust One Class Classification (DROCC) that is both applicable to most standard domains without requiring any side-information and robust to representation collapse. DROCC is based on the assumption that the points from the class of interest lie on a well-sampled, locally linear low dimensional manifold. Empirical evaluation demonstrates that DROCC is highly effective in two different one-class problem settings and on a range of real-world datasets across different domains: tabular data, images (CIFAR and ImageNet), audio, and time-series, offering up to 20% increase in accuracy over the state-of-the-art in anomaly detection. DROCC's code is available at https://github.com/Microsoft/EdgeML/. |
|
abstract /
paper /
arxiv /
presentation
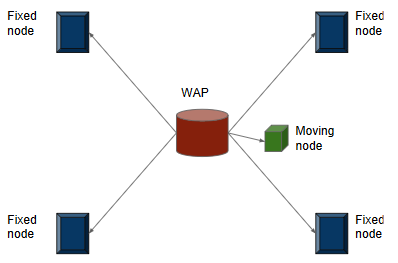
The Global Navigation Satellite Systems (GNSS)like GPS suffer from accuracy degradation and are almostunavailable in indoor environments. Indoor positioning systems(IPS) based on WiFi signals have been gaining popularity.However, owing to the strong spatial and temporal variationsof wireless communication channels in the indoor environment,the achieved accuracy of existing IPS is around several tens ofcentimeters. We present the detailed design and implementationof a self-adaptive WiFi-based indoor distance estimation systemusing LSTMs. The system is novel in its method of estimatingwith high accuracy the distance of an object by overcomingpossible causes of channel variations and is self-adaptive tothe changing environmental and surrounding conditions. Theproposed design has been developed and physically realized overa WiFi network consisting of ESP8266 (NodeMCU) devices. Theexperiments were conducted in a real indoor environment whilechanging the surroundings in order to establish the adaptabilityof the system. We compare different architectures for this taskbased on LSTMs, CNNs, and fully connected networks (FCNs).We show that the LSTM based model performs better amongall the above-mentioned architectures by achieving an accuracyof5.85cm with a confidence interval of93%on the scale of(8.46m x6.98m). To the best of our knowledge, the proposedmethod outperforms other methods reported in the literature bya significant margin. |
|
abstract /
paper /
arxiv
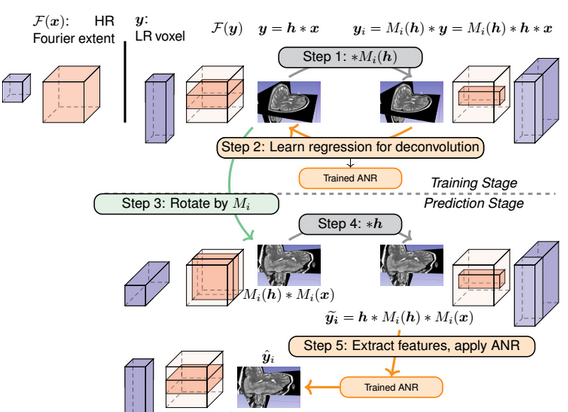
Magnetic resonance (MR) images (MRI) are routinely acquired with high in-plane resolution and lower through-plane resolution. Improving the resolution of such data can be achieved through post-processing techniques knows as super-resolution (SR), with various frameworks in existence. Many of these approaches rely on external databases from which SR methods infer relationships between low and high resolution data. The concept of self super-resolution (SSR) has been previously reported, wherein there is no external training data with the method only relying on the acquired image. The approach involves extracting image patches from the acquired image constructing new images based on regression and combining the new images by Fourier Burst Accumulation. In this work, we present four improvements to our previously reported SSR approach. We demonstrate these improvements have a significant effect on improving image quality and the measured resolution. |
|
|

|
abstract /
bibtex
Open source repository for all the research outputs on resource
efficient Machine Learning from Microsoft Research India. It contains scalable and multi-framework
compatible implementations of Bonsai, ProtoNN, FastCells, EMI-RNN, ShaRNN, RNNPool, DROCC, a tool
named SeeDot for fixed-point compilation of ML models along with applications such as on-device
Keyword spotting and Gesturepod.
@misc{edgeml03,
author = {{Dennis, Don Kurian and Gaurkar, Yash and
Gopinath, Sridhar and Gupta, Chirag and
Jain, Moksh and Kumar, Ashish and
Kusupati, Aditya and Lovett, Chris and
Patil, Shishir Girish and Simhadri, Harsha Vardhan}},
title = {{EdgeML: Machine Learning
for resource-constrained edge devices}},
url = {https://github.com/Microsoft/EdgeML},
version = {0.3},
}
|
|
|
|
abstract /
Technical Report
Hardware-in-the-loop simulations are very commonly used to test controller design and monitor how the controller responds, in real time, to realistic virtual stimuli. In an HIL simulation, a real-time computer is used as a virtual representation of the plant model and a real version of the concerned controller. Most of these dynamical systems are in the form of coupled differential equations, and digital computers tend to be terribly slow at iteratively approximating solutions to such systems. The notion of using analog computing grids to efficiently solve differential equations (in hardware) has been well accepted in the research fraternity, and proves to be a faster way to solve linear dynamical systems. In this project, we demonstrate a digitally programmable analog computer, which can solve linear dynamical systems with upto 5 state variables. The system is capable of working in real time, since there are no moving parts once the configuration is set and the system is programmed. The system is capable of being driven by upto 5 forcing functions, and can represent any linear dynamical system upto order 5. It consists of active devices to implement integrators, gain blocks and inverter blocks using operational amplifiers, along with passive components to emulate the system matrix. These blocks will be linked together using analog switches which would be controlled by signals given by a microcontroller. For our first prototype, we assume B and C to be identity, for the sake of simplicity. In this report, we present the design philosophies, layout descriptions, experimental results and analyses of two prototypes ㅡ DPAC-𝜷 and DPACv1.0. The DPAC-𝜷 is a miniature version of the DPACv1.0, to emulate second order systems, and features a block-modular structure and mechanical switches, allowing easy configuration of the system matrix and operational parameters. The DPACv1.0 features a single PCB, is interfaced and controlled using a microcontroller, and is capable of solving the linear dynamical system in real time. |

|
|
|
|

|
10-707: Advanced Deep Learning, Spring '24, CMU
10-417: Intermediate Deep Learning, Fall '23, CMU
BB101: Biology, Fall '17, IIT Bombay
Teaching basics of Programing to High School Students in hometown, Pandemic '2020, Udaipur |
|